- 초기 빅데이터 플랫폼:
엔드 투 엔드로 각 서비스 애플리케이션으로부터 데이터를 배치로 모음
데이터를 배치로 모으는 구조는 유연하지 못하고, 실시간으로 생성되는 데이터들에 대한 인사이트를 서비스 애플리케이션에 빠르게 전달하지 못함
또한 원천 데이터로부터 파생된 데이터의 히스토리를 파악하기가 어려웠고, 계속되는 데이터 가공으로 인해 데이터가 파편화되면서 데이터 거버넌스를 지키기 어려웠음. 거버런스란 빅데이터에 대한 체계적인 관리와 통제를 의미. 예로 들면 프라이버시나 품질, 데이터 생명주기와 같은 것을 의미. 이러한 것을 해소하기 위해 나온 것이 람다 아키텍처.
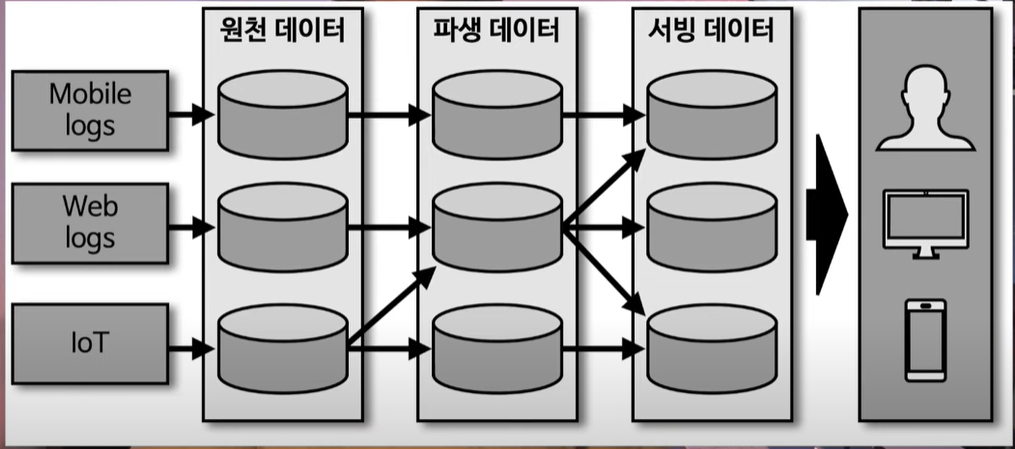
- 람다 아키텍처
트위터에서 스트리밍 컴퓨팅에 있었던 Nathan Marz에 의해서 소개된 아키텍쳐로, 실시간 분석을 지원하는 빅데이타 아키텍쳐(출처)
람다 아키텍처는 3가지 레이어(배치 레이어, 서빙 레이어, 스피드 레이어)로 구분.
배치 레이어는 배치 데이터를 모아서 특정 시간, 타이밍마다 일괄 처리함. 스파크잡과 같은 대규모 잡이 해당
서빙 레이어는 가공된 데이터를 데이터 사용자, 서비스 애플리케이션이 사용할 수 있도록 데이터가 저장된 공간. 하둡이 대표적임. 대규모 대용량 데이터를 안정적으로 저장.
스피드 레이어는 서비스에서 생성되는 원천데이터를 실시간으로 분석하는 용도로 사용. 배치 데이터에 비해 낮은 지연으로 분석이 필요한 경우에 스피드 레이어를 통해 데이터를 분석. 보통 카프카와 같은 이벤트 스트리밍 플랫폼이 스피드 레이어에 위치.

- 람다 아키텍처의 한계
데이터를 배치 처리하는 레이어와 실시간 처리하는 레이어를 분리한 람다 아키텍처는 데이터 처리 방식을 명확히 나눌 수 있었지만 레이어가 2개로 나뉘기 때문에 여러가지 단점이 생김
첫번째, 데이터를 분석, 처리하는데 필요한 로직이 2벌로 각각의 레이어에 따로 존재해야 함.
두번째, 배치 데이터와 실시간 데이터를 융합하여 처리해야 할 때는 다소 유연하지 못한 파이프라인을 생성 해야 한다.
한 개의 로직을 추상화하여 배치 레이어와 스피드 레이어에 적용하는 형태인 서밍버드라는 플랫폼도 있었지만 완벽히 해결되는 것은 아니였음. 컴파일을 한번 하더라도 배포는 두번 이루어져야 하고, 디버깅과 로깅 그리고 모니터링도 결국에는 각각 해야했음. 람다 아키텍처를 해소하기 위해 제이 크렙스는 카파 아키텍처를 제안함.
- 카파 아키텍처
제이 크렙스는 카프카를 최초로 고안한 개발자이자 전 링크드인 팀장, 현재는 컨플루언트 CEO임. 제이 크렙스는 람다 아키텍처의 단점으로 지목되었던 로직의 파편화, 디버깅, 배포, 운영 분리에 대한 이슈를
제거하기 위해 배치 레이어를 제거하는 방안을 고려함.
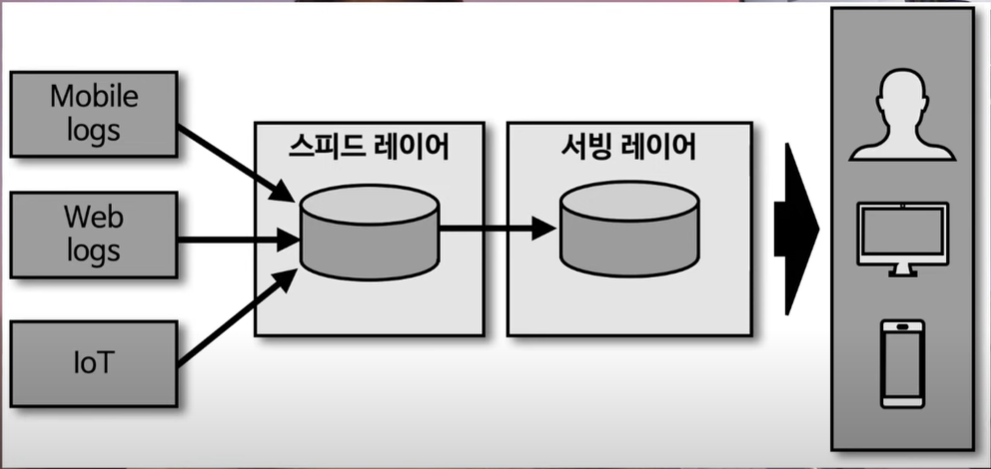
카파 아키텍처는 스피드 레이어에서 데이터를 모두 처리할 수 있었으므로 엔지니어들은 효율적으로 일할 수 있었음.
- 스트리밍 데이터 아키텍처
2020년 카프카 서밋에서 제이 크랩스는 카파 아키텍처에서 서빙 레이어를 제거한 아키텍처인 스트리밍 데이터 레이크를 제안함. 카파 아키텍처를 살펴보면 데이터를 사용하는 고객을 위해 스트림 데이터를 서빙 레이어에 저장함. 스피드 레이어로 사용되는 카프카에 분석과 프로세싱을 완료한 거대한 용량의 데이터를 오랜 기간 저장하고 사용할 수 있다면 서빙 레이어는 제거되어도 된다고 생각함. 오히려 서빙 레이어와 스피드 레이어가 이중으로 관리되는 이중 리소스를 줄일 수 있었음. 기존에 사용하던 하둡을 카프카로 대처하는, 누구도 생각하지 못한 혁신적인 생각이였음. 아직은 카프카를 스트리밍 데이터 레이크로 사용하기 위해 개선해야 하는 부분이 있음.
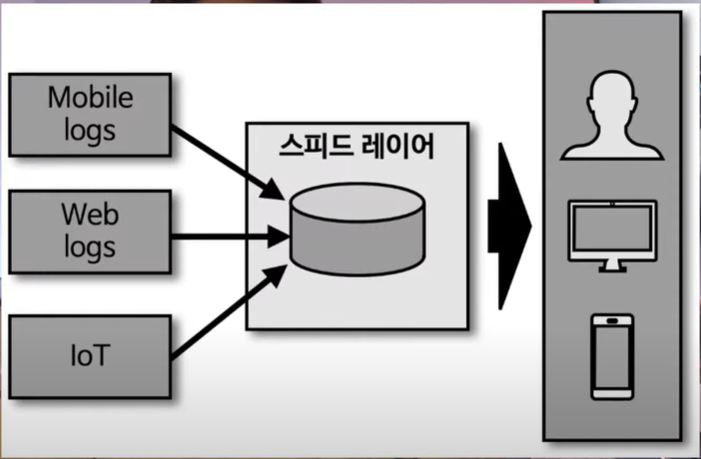
출처: https://www.youtube.com/watch?v=U5G-i73Wb6U
'IT study > 99. etc: IT 상식' 카테고리의 다른 글
| cmd(Command Prompt)란? (0) | 2023.11.22 |
|---|---|
| 프로그래밍 도구 설치 후 cmd 재시작하는 이유 (0) | 2023.11.22 |
| 컴퓨팅 및 데이터 처리 환경: 엣지, 온프레미스, 클라우드 (0) | 2023.08.18 |
| iso (0) | 2022.05.24 |
| 데이터 사일로(Data silo) (0) | 2022.04.21 |
